Ad space available
Memahami Transformer: Arsitektur di Balik ChatGPT
Panduan lengkap memahami arsitektur Transformer, fondasi dari semua model bahasa modern seperti GPT, BERT, dan LLaMA. Dijelaskan dengan analogi sederhana.
Memahami Transformer: Arsitektur di Balik ChatGPT
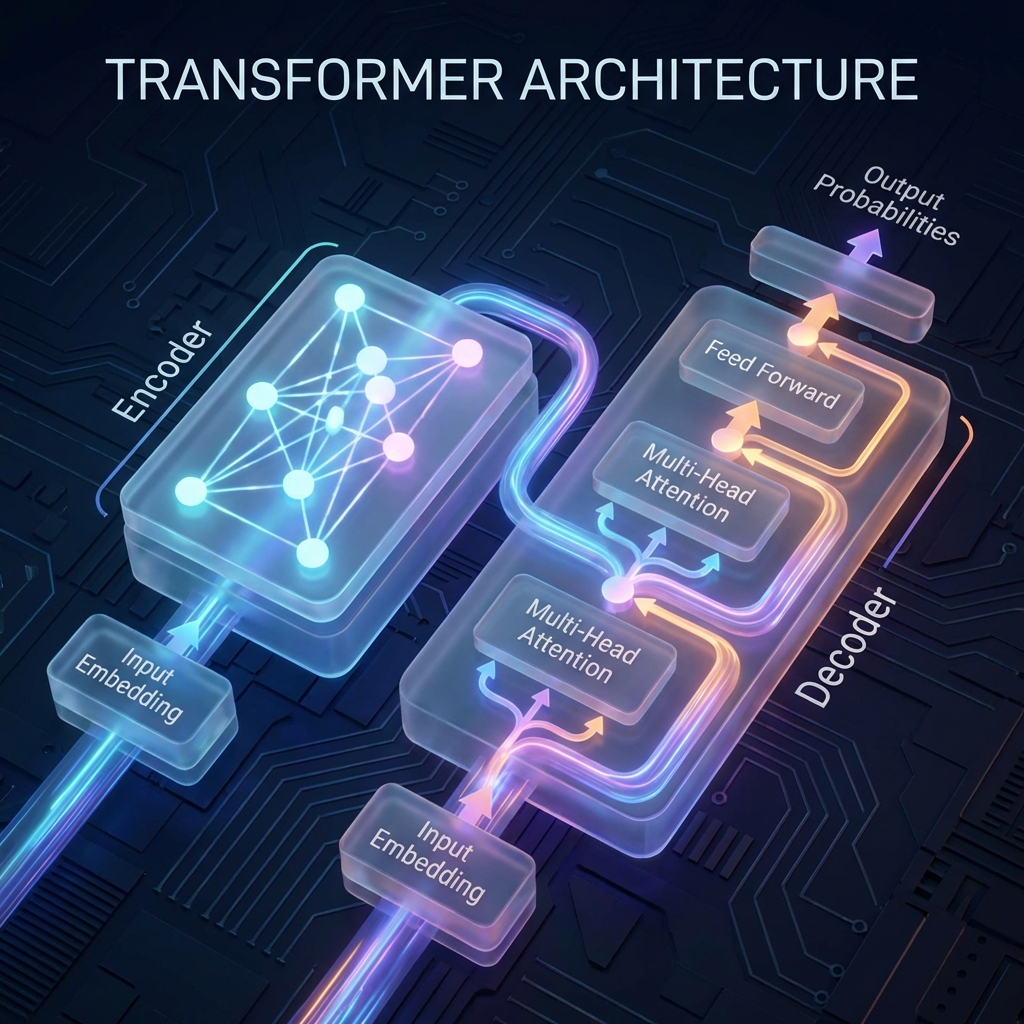
Transformer adalah arsitektur neural network yang menjadi fondasi dari semua model AI modern seperti ChatGPT, GPT-4, dan LLaMA. Paper aslinya, "Attention Is All You Need", dirilis oleh Google pada 2017 dan mengubah sepenuhnya cara kita membangun model AI.
Mengapa Transformer Penting?
Sebelum Transformer, model bahasa menggunakan RNN (Recurrent Neural Networks) yang memproses data secara berurutan. Ini lambat dan sulit menangkap hubungan antara kata-kata yang berjauhan.
Transformer memungkinkan pemrosesan paralel, yang berarti training bisa 10-100x lebih cepat dibanding RNN pada hardware modern.
Komponen Utama Transformer
1. Self-Attention Mechanism
Self-Attention adalah "mata" dari Transformer. Mekanisme ini memungkinkan model untuk memperhatikan semua posisi dalam input secara bersamaan.
def self_attention(query, key, value):
# Hitung attention scores
scores = torch.matmul(query, key.transpose(-2, -1))
scores = scores / math.sqrt(d_k)
# Apply softmax untuk mendapat weights
attention_weights = F.softmax(scores, dim=-1)
# Multiply dengan values
output = torch.matmul(attention_weights, value)
return output
2. Multi-Head Attention
Alih-alih satu attention, Transformer menggunakan multiple "heads" yang masing-masing bisa fokus pada aspek berbeda dari input.
3. Feed-Forward Networks
Setelah attention, setiap token diproses melalui fully-connected layers:
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.linear2(self.relu(self.linear1(x)))
Bagaimana Training Dilakukan?
Model Transformer ditraining dengan memprediksi token berikutnya dalam sequence. Ini disebut causal language modeling:
- Input: "Saya suka makan"
- Target: "suka makan nasi"
- Model belajar memprediksi setiap token berikutnya
Implementasi Praktis
Untuk mulai eksperimen dengan Transformer, kamu bisa menggunakan library seperti Hugging Face:
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load pre-trained model
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# Generate text
input_text = "Artificial Intelligence adalah"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs, max_length=50)
print(tokenizer.decode(outputs[0]))
Kesimpulan
Transformer telah merevolusi bidang AI dan menjadi arsitektur standar untuk:
- Large Language Models (GPT, LLaMA, Gemini)
- Computer Vision (ViT, CLIP)
- Speech (Whisper)
- Multimodal (GPT-4V, Gemini)
Ingin belajar lebih dalam? Baca paper original "Attention Is All You Need" dan coba implementasi sendiri di PyTorch!
Artikel ini adalah bagian dari seri Tutorial AI dari Rekayasa AI. Bergabunglah dengan komunitas Discord untuk diskusi lebih lanjut!
Ad space available
Ditulis oleh
Tim Rekayasa AI
Kontributor Rekayasa AI yang passionate tentang teknologi AI dan dampaknya di Indonesia.